In last week’s blog post, I showed you how we use Lucene.Net, a code library and document database we use to manage DoneDone’s search catalog. I detailed how we structure the documents in our database and how we write search queries against it.
In the second of our two posts, I’ll dive into how we actively manage the Lucene search database itself. How do we add new documents? How do we update existing ones? What happens if we need to rebuild the catalog? Let’s find out!
Adding documents
When someone creates a new issue or adds a new comment, the data is immediately stored in our master relational database. However, it isn’t immediately added to our search database. Instead, we run a separate, out-of-band process to update our search database. We do this mainly to avoid any additional performance weight to the application.
To accomplish this, we created a standalone processor which we’ll call the LuceneUpdater. It lives on a jobs server, separate from our web and master database servers. Every five minutes, it queries the master database to determine what documents need to be added to the search database.
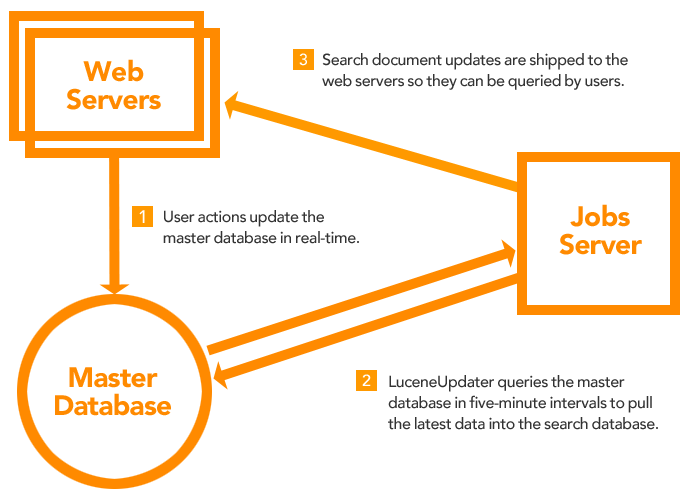
In our first blog post, we saw how each document in the search database essentially maps to one issue history record in our master database. In order for LuceneUpdater to know what new records have been added to the master database since it last ran, it stores the IssueHistoryID of the last record processed at the end of each run.
Because these IDs auto-increment in the master database, when it queries the master database for the next run, it grabs all issue histories whose ID is greater than the most recently stored IssueHistoryID.
So, where does LuceneUpdater store this all-important ID? It creates a solitary Lucene document in a separate folder path which contains a field named LastIssueHistoryIDUpdated. Each time LuceneUpdater runs, it first looks up this document and retrieves the value of LastIssueHistoryIDUpdated.
If the document doesn’t exist, LuceneUpdater simply starts from the beginning again (i.e. the very first IssueHistoryID). So, if we ever wanted to dump and rebuild the search catalog, we would just manually delete both the search database documents and this one-off document that stores LastIssueHistoryIDUpdated.
LuceneUpdater also adds a cap to the number of records it will process in one go. So, if we rebuild the search catalog, it won’t try to create millions of documents on one attempt (as of this writing, there are nearly 12 million issue history records globally in DoneDone). Instead, it will build a maximum of 500,000 documents per cycle. It will then store the last issue history record ID, and start with the next highest one five minutes later. Eventually (on the order of a couple of hours right now), LuceneUpdater will catch up to all the issue history records in the master database.
Of course, a complete rebuild is an exceptional case. During a normal five minute cycle at peak periods, there may be a couple hundred records to process at most.
Managing updates and deletes
You might think this is all we need to do to keep the search database updated with our master database, but there are actually several other scenarios we need to account for:
- At any point, someone can decide to update an issue. If they change the title, description, status, or priority of the issue, these updates need to be reflected in the search database.
- Users can also move an issue to a new project. Not only does this change an issue’s project, but also its number. (Note: issue numbers are assigned sequentially per project. So, if issue #123 in Project A is moved to a Project B that only has 21 issues, it will have a new number – #22). Both of these updates need to be reflected in all documents relating to moved issues. Otherwise, they’d not only see outdated projects and issue numbers, but could also see incorrect results when filtering search queries by project.
- Users can also edit their issue comments for up to 30 minutes after they’re added. Naturally, the search document corresponding to the issue history record also needs to be updated.
- In addition, someone can delete an issue altogether. When an issue is deleted, it shouldn’t be available anywhere, including a text search.
Because the search database is managed asynchronously from the actions that happen within the application, we need a way of tracking all of these updates that might occur between each run of the LuceneUpdater.
We do this by leveraging another part of the DoneDone architecture—our caching layer. In our case, we use Membase (a key/value store) as our persistent cache. We primarily use Membase to store a number of different types of data to improve the performance of the app in various ways.
For the purposes of maintaining the search database, we store three additional key/value pairs to account for all of the potential issue update scenarios I just described. I’ll briefly describe each Membase key/value pair and then detail how we employ them in LuceneUpdater.
Membase key nameValueIssueUpdateForSearchStores a list of issue IDs. Each time an issue’s title, description, file attachments, status, priority, or project is updated, the issue’s ID is added to the list.IssueHistoryUpdateForSearchStores a list of issue history IDs. Each time a comment for an issue history is updated by a DoneDone user, the history ID is added to this list.IssueDeleteForSearchStores a list of issue IDs. Each time an issue is deleted from the master database, the ID is tracked in this list.
The complete LuceneUpdater workflow
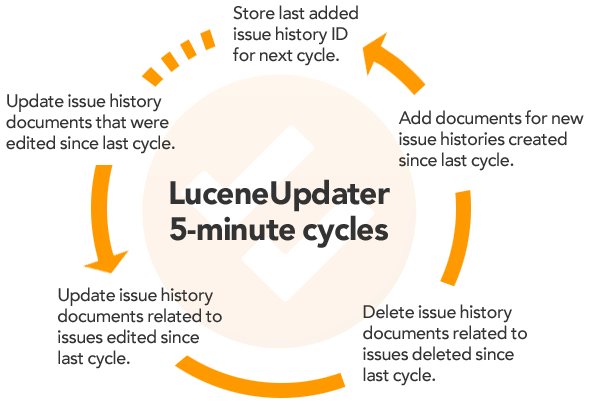
Each time LuceneUpdater runs, here’s what happens:
First, it reads the list of issue history IDs from the IssueHistoryUpdateForSearch record in Membase. It then queries the master database, grabbing the relevant data from the issue history records with a matching ID in the list. Then, LuceneUpdater queries the search document store for an exact match on the IssueHistoryID field. For each returned document, the other fields are updated to match the data from the resultset in the master database. Finally, it removes IssueHistoryUpdateForSearch from Membase.(Note: the record will be re-added/updated in between updater runs should there be any issue history updates in that time span.)
Next, LuceneUpdater reads the list of issue IDs off the IssueUpdateForSearch record in Membase. Similarly, it queries several tables in the master database to gather the necessary history data relating to each issue whose ID exists in the list. Then, LuceneUpdater queries the search document store for an exact match on the IssueID field. Unlike the issue history update, there will likely be several document matches on one IssueID field (since a new document is made for each issue’s history).
Fields like IssueNumber, IssueTitle, and ProjectID are updated to match the data from the master database. However, the description field is only modified for documents with an IssueHistoryType of CREATION, since all other documents would relate to an issue history record rather than the issue itself (see our first post for a deeper explanation). When the process is completed, IssueUpdateForSearch is removed from Membase.
LuceneUpdater then moves on to removing documents in the search database related to deleted issues. After reading the list of issue IDs from IssueDeleteForSearch, it then queries the search database for an exact match on IssueID and removes each of document related to a deleted issue. When the process is completed, IssueDeleteForSearch is removed from Membase.
With the issue history updates, issue updates, and deletes complete, LuceneUpdater then adds all new issue histories in the manner we discussed earlier.
Accepting the right amount of staleness
Because we update our search database asynchronously, we introduce a potential problem. The search database will never be fully updated in real-time. Any updates or additions made in the five minute span between the re-execution of LuceneUpdater won’t appear until the next run. In other words, there is, at most, a five-minute delay.
For the most part, this is fine. It’s good enough. We’re willing to take the tradeoff of a small amount of staleness for all the benefits of a separately maintained and updated search catalog.
However, one scenario might not be good enough for our customers—deleting an issue. Suppose someone accidentally entered in production credentials into an issue and only realized it a half hour later. If they go back to delete the issue, the issue details would still exist in the search database until the next LuceneUpdater run, even if only for a few minutes.
We wanted issue deletes to be instantaneous. They should be gone from the site the instant someone deletes it and they shouldn’t be accessible via the search.
To achieve this, we rely on Membase again. When a set of documents are returned from a search request, prior to displaying these results on screen, we read the IssueDeleteForSearch key/value pair. If any issue IDs in the list match the IssueID for a document, that document is skipped when assembling the search results view. So, even though the documents for a deleted issue might not yet be removed by LuceneUpdater, they will never get included on any search queries.
In summary, we’re OK with content taking up to five minutes to update. With deletes, we circumvent the search database to ensure what’s deleted doesn’t resurface.
Optimizing the index
Lucene’s library also comes with a method in its IndexWriter class called Optimize(). This method reorganizes the document structure to make sure the searches work as quickly as possible (the details of what goes on behind-the-scenes I’ll leave to the Lucene team). We run a separate process to ensure the search document indexes are optimized once per day.
———
So there we have it. In the past two blog posts, you’ve seen how we use Lucene.Net to build our search database along with some of the interesting challenges we face with keeping it up-to-date. If you’re thinking of implementing a search catalog in your application, I hope this insight helps you out.